Unless you’ve been living under a rock for the last couple years, you’ve likely heard all you ever wanted to hear about big data in healthcare (well, that is, unless your job is intimately tied to it, which will likely be more of you as time goes on). That said, the opportunities to leverage big data are fantastic and will undoubtedly lead to significant advances in the areas of new technologies, personalized medicine, disease research, diagnostics, and more.
As such, I’m rarely tired of hearing of the trends and directions this aspect of the industry is headed. With that in mind, I was thrilled to have the opportunity to speak with Paul Terry, the CEO of PHEMI Systems, a company that specializes in the management and organization of healthcare data. He pretty much breathes big data and the healthcare sector is certainly a focus area.
Sean Fenske: Thank you for your time today to speak with me about big data in the healthcare space. First, can you give me a quick overview of what PHEMI does?
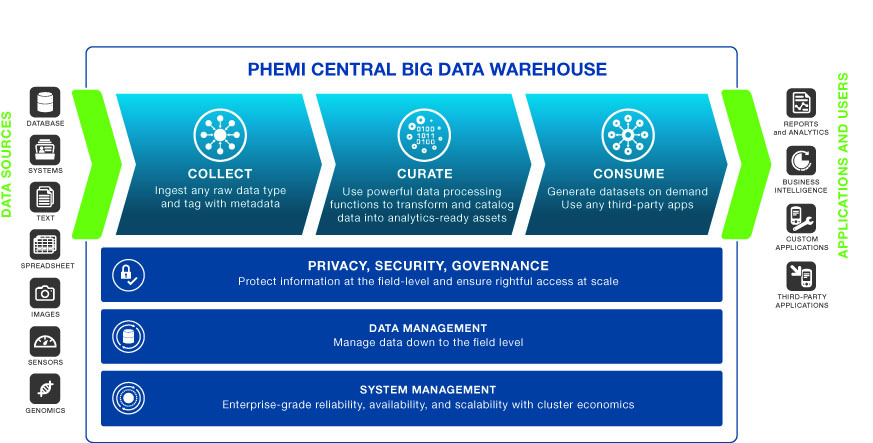
Paul Terry: We use big data to create vast knowledge repositories, with the indexing and cataloging to find the information you need whenever you need it. Take Google, which uses big data to aggregate all public web pages in the world into one space. Imagine if you could do that for private data, like healthcare records. That’s what PHEMI does.
Fenske: How did the company get started? What was the inspiration?
Terry: PHEMI was founded by medical people working in critical care. When physicians need information, it has to be at their fingertips. But that data is often spread across hundreds or thousands of databases. A hospital would need half a million connections to connect a thousand databases. Currently, they may have 10. So most data is left siloed, stranded. And it’s not just an issue in the clinical space — the same fragmentation affects medical research, healthcare business operations, healthcare policy, and many other areas.
We pull all that data together. Now, when you do that, you have an ethical, moral, and legal responsibility to protect that information. We’ve made it possible to aggregate billions of records with privacy, security, and governance for every single piece of data. That’s our competitive advantage.
Fenske: You bring up the issue of security, which is without question a huge issue these days. Can you speak more to the issue of data security within the healthcare space?
Terry: When you aggregate all of your healthcare data into one giant repository, what’s to stop anybody from doing anything they want with it? The top big data priority for healthcare organizations is security — stopping information from being leaked, controlling what people see, and auditing that so you know you’re protecting people’s privacy.
But it’s a complicated problem, because in healthcare, different people are allowed to see different things. A clinician is allowed to see some things, a business process analyst others, an affiliated researcher still others. And it all depends on context.
If you’re going to create a massive library of healthcare data, you need a very aggressive librarian at the door controlling what you see and how you see it, and guiding you to just the information you need for your specific purpose.
Fenske: Are healthcare organizations and facilities doing enough to ensure their data is secure?
Terry: In the U.S., there are major fines if you have a data breach, so healthcare organizations do take security very seriously. But often, it’s at the cost of not being able to use their data as well as they could. This is the irony: if you’re not going to use the data, the best security is not to collect it at all.
Part of the issue is that people confuse security and privacy. Security is about ensuring that nobody has access to information. Privacy is about getting the right information to the right person at the right time. I’d argue that healthcare organizations could do a better job securing their data, but the bigger issue is that they could be making more use of their data to help people.
Fenske: Let’s explore that point for a moment. Everyone is talking about big data and the collection of big data within healthcare and how it’s going to make an enormous difference in the industry. But what is really happening with big data today? What’s actually happening at the moment?
Terry: If you divide healthcare into research and clinical operations, big data exists today largely in the clinical space, where it’s used to improve things like hospital operations, staffing, and readmissions. In research, it’s still limited to early adopters, like the National Institutes of Health’s genomics project.
Research and clinical worlds are typically quite separate, but when they come together, we see dramatic advances. One example is HIV, where the intersection of clinical and research data may eradicate the virus within a generation.
When you do that, however, the biggest challenge is privacy, security, and governance of data, especially around compliance. Healthcare is a huge industry — four times the size of the U.S. retail banking industry. So there is enormous potential for transformational advances if we can solve that problem.
Fenske: With that said, how else will big data affect future healthcare applications and technology?
Terry: One major advantage of big data is that you can write and refine applications on top of it very quickly. You can collect petabytes of data, but if it takes forever to find what you want, it’s not worth having. If it took Google an hour to do a search, no one would use it. But when it takes 0.3 seconds, you can achieve an entirely new level of information awareness, and apply it to next-generation applications and services.
Consider how Google uses public data to power maps, search, etc. The same potential exists in healthcare, provided you solve the privacy and governance problem.
Fenske: That’s actually a perfect lead into my next question. I’ve heard that the collection of big data isn’t the challenge but rather the analysis of it. Do you think this holds true for the healthcare industry?
Terry: No, in healthcare, I would argue the opposite. It’s very easy these days to create an analytics company, but the biggest problems you’ll face are proper access and data quality.
The access problem — assuring appropriate privacy and governance — is what we’re primarily attacking. But most people in this space would agree that healthcare data today is often dirty, incomplete, and not collected very well.
Once you solve the problem of collecting, securing, and cleaning the data, and then allowing people to get it to the right person at the right time, then analytics companies can add a lot of value. But if you don’t have the right data, the analytics don’t matter.
Fenske: Does PHEMI offer solutions for the analysis of big data for healthcare applications?
Terry: We don’t do traditional analysis, but we make data analytics-ready. We specialize in collecting healthcare data, securing it, and creating a massive repository of cross-indexed information. Think of a catalog indexing all the information in a large library. If you can’t find what you need, that library is not very helpful. That’s the problem that we solve.
We go deep inside the data, cataloging even information within a record, and create data structures that allow us to represent the data in many different ways — graphically, semantically, traditional tabular databases, etc. So when our customers work with analytics companies, they can present their data to them in a way that analytics applications can more effectively consume it.
Fenske: Where do the unrealized opportunities for big data in healthcare exist?
Terry: One is just reducing the number of databases. One large healthcare organization we work with has 4,000 databases. The more you have, the more staff you need to operate them, the more you spend on licensing. So there’s huge potential for reductions in costs and complexity. Second, big data, unlike traditional SQL databases, is designed to scale, so the marginal costs of managing millions of customers and billions of assets decrease as you grow.
There’s also a huge opportunity to automate the capture of more types of unstructured data — lab reports, consult letters, genomic and microbial data, etc. — and allow it to be easily indexed and catalogued in the data store, which, in turn, will reduce manual entry and improve data quality. Moving to a schema-less design will make it much faster and easier to continually add new data sources. For system and application designers, it will mean they can more easily prototype, test, and deploy new applications to respond faster to changing requirements.
Fenske: How are companies misusing big data in healthcare?
Terry: I wouldn’t say that companies are misusing big data, so much as just dipping their toes in, or not using it at all. Some countries, like England, are doing very well with big data, but U.S. healthcare organizations are falling behind.
Fenske: Why is that?
Terry: Part of the reason may be this fallacy we see around big data, that you can just download it from the internet and switch it on. Companies that do that quickly run into the reality that there’s a lot more to it. It’s like the early days of Linux and open source. Yes, you can download and install it, but you need a lot of things around it to make it work effectively.
This is especially true when designing the healthcare systems and applications that will take advantage of the organization’s data. If you’re putting the onus on system and application developers to address this hugely complex privacy and governance problem, for example, you end up with applications that are more brittle, difficult to align with frequently changing roles and permissions, and slower and more expensive to develop.
Fenske: What’s the next phase for big data in healthcare? What’s on the horizon?
Terry: We expect to see big data pick up significantly on the research side of healthcare. It’s already starting in genomics. You’ve probably heard the buzzword “personalized medicine,” pulling data from many information sources to create an individualized view of healthcare. We expect to see much more of that.
On the clinical side, we see many more applications of big data to improve operations — everything from nurse overtime to readmissions to using analytics to improve hospital efficiency. In practical terms, big data will evolve over time from basic form-based server interfaces to supporting comprehensive productivity applications with embedded workflows, automated pre-population of forms, decision support, and automated documentation package creation. Also, as U.S. healthcare providers start to consolidate into larger accountable care organizations (ACOs), aggregating data from different EMR systems will drive more implementations.
Longer term, we see hospitals moving away from doing their own IT. Big data with security and compliance will likely become a private cloud service. We expect to see companies starting up in the next five to 10 years strictly around improving healthcare operations.
Fenske: Before we wrap up, do you have any other comments you’d like to share?
Terry: Healthcare is a very conservative and risk-averse industry, steeped in compliance issues. So there is a lot of ambiguity, and it can be quite challenging. We see the evolution of big data in healthcare being less a blinding flash of light than vespers appearing out of the mist.
It will be interesting to see when the tipping point happens. Once the EMR mandate takes full effect nationwide, we will have the mechanisms in place to collect data. The next question will be, “OK, so now what?” That’s when the real break will happen. As healthcare starts using all of its data to better inform what they do, I think we’ll see sweeping change.
Most major U.S. companies and increasingly, healthcare organizations, now have a “chief data officer,” whose job is to control and maximize the organization’s data, because they recognize that information is power. There is enormous potential to solve the biggest issues in healthcare — improving outcomes, lowering costs, understanding disease — when organizations harness their data.